



I am a self-taught AI/ML Developer having experience in both Tensorflow and PyTorch frameworks. Currently, exploring advanced NLP. I am a sophomore at Harcourt Butler Technical University and have completed my Higher Secondary Education in 2021 and High School from in 2019 from Indus Valley Public School . I am currently looking for opportunities On-site/Remote.
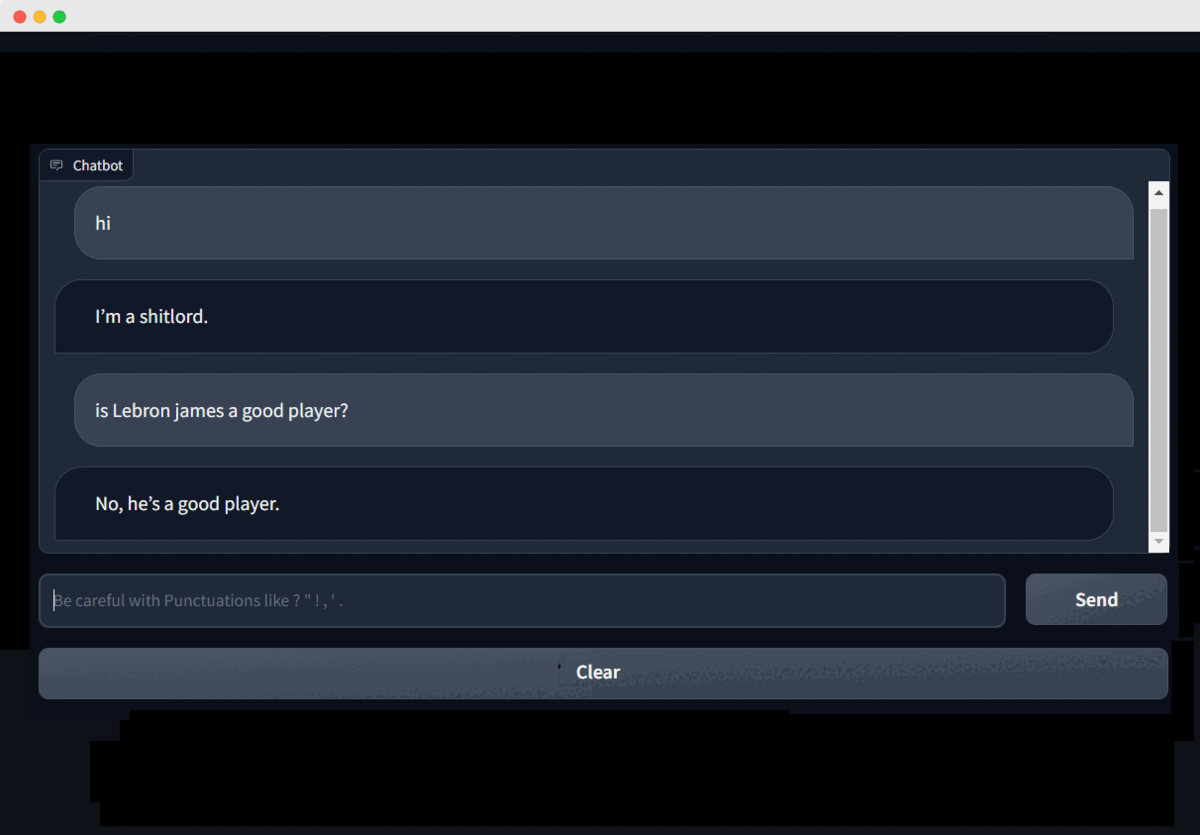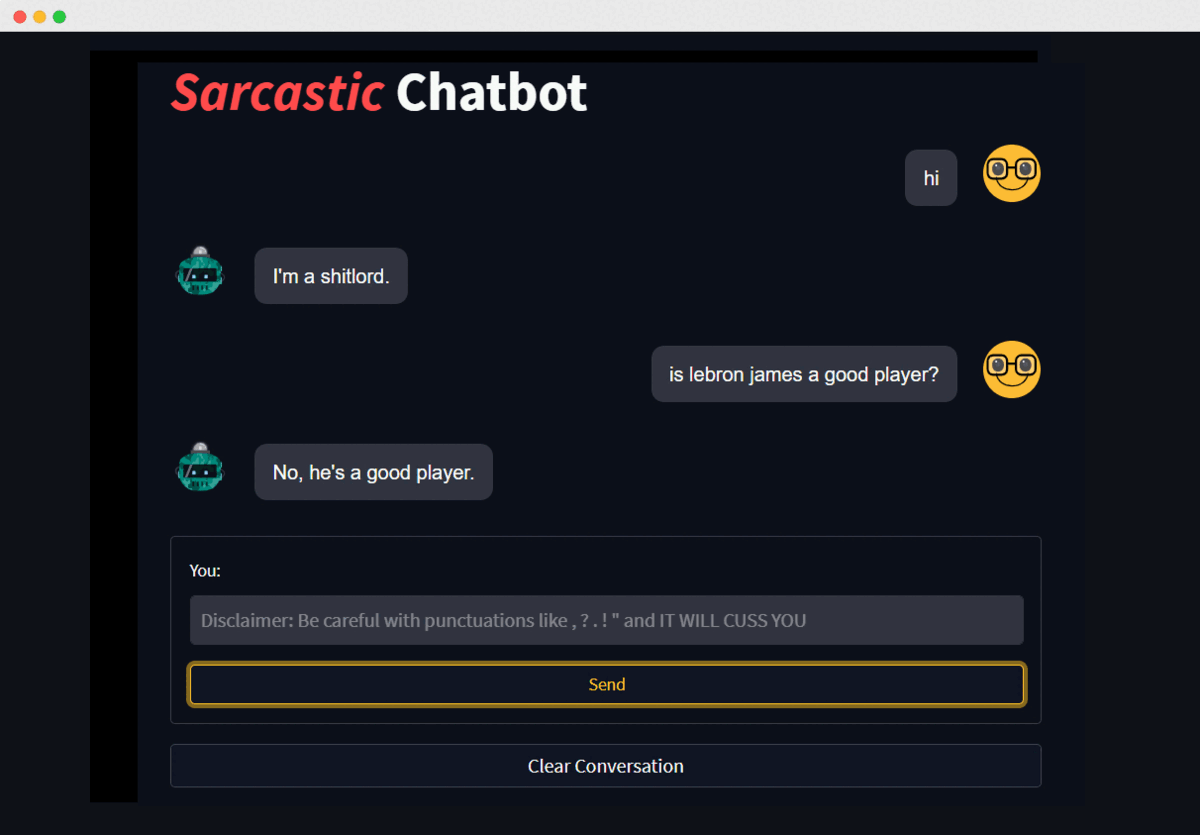
This chatbot is a fine-tuned version of T5(Text-to-Text Transfer Transformer) for conversational purposes. Chatbot is incorporated with MongoDB for saving and downloading chats with faster query. Dataset was retrieved from reddit comments of subreddits which indulge in mockery and sarcasm. It is deployed using Streamlit and gradio framework. Special thanks to Reddit for making the dataset available publicly.
This is a NMT (neural machine translation) model using Seq2Seq with Bahdanau attention mechanism comprising of GRU RNN cell. Served using FastAPI and achieved BLEU score of 40 by training on 200K samples (Hinglish to English). It transforms Hinglish text (in roman script) to English text.` Special thanks to Google research for making the dataset available publicly on github. Still, scarcity of Hinglish corpus(Roman script) is affecting the BLEU score.
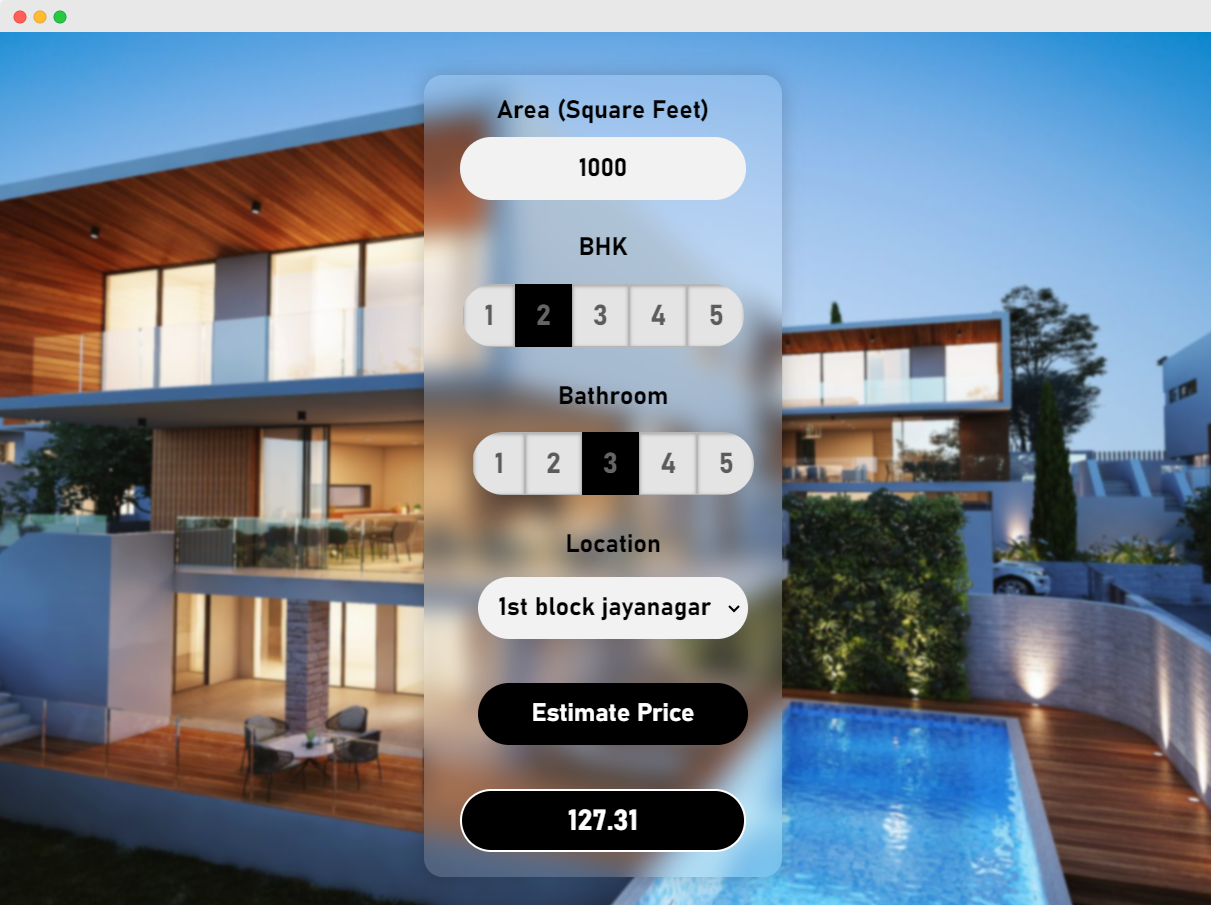
This is a end to end ML project which implemented Linear Regression model using dockers and automated workflow with Github Actions. I have used Flask Server as backend and HTML, CSS for frontend. Special thanks to AMITABHACHAKRABORTY for making the Bengaluru price dataset available publicly on kaggle.
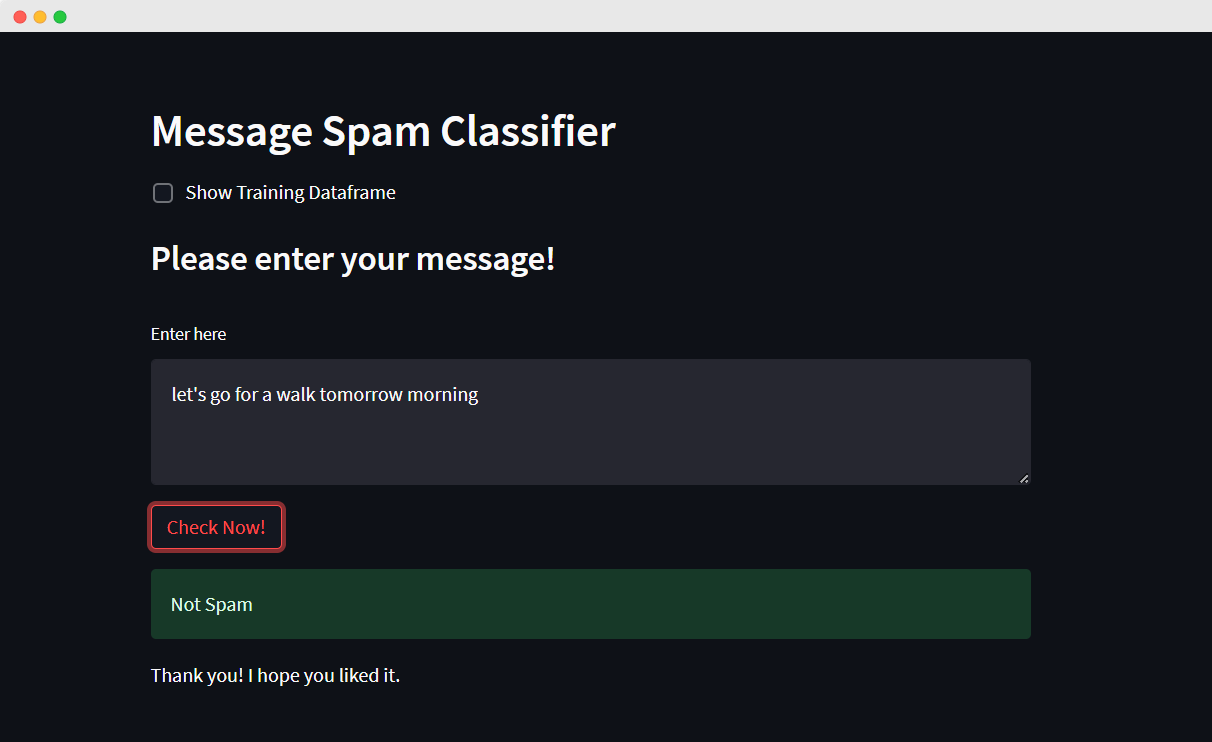
This is an end-to-end NLP project based on SMS Spam Collection Dataset available on kaggle capable of predicting whether the message is ham or spam with good precision and accuracy using a classifier. Note: Please ensure you have the necessary libraries installed before running this project. Special thanks to UCI Machine Learning Repository for making the dataset available publicly on kaggle.
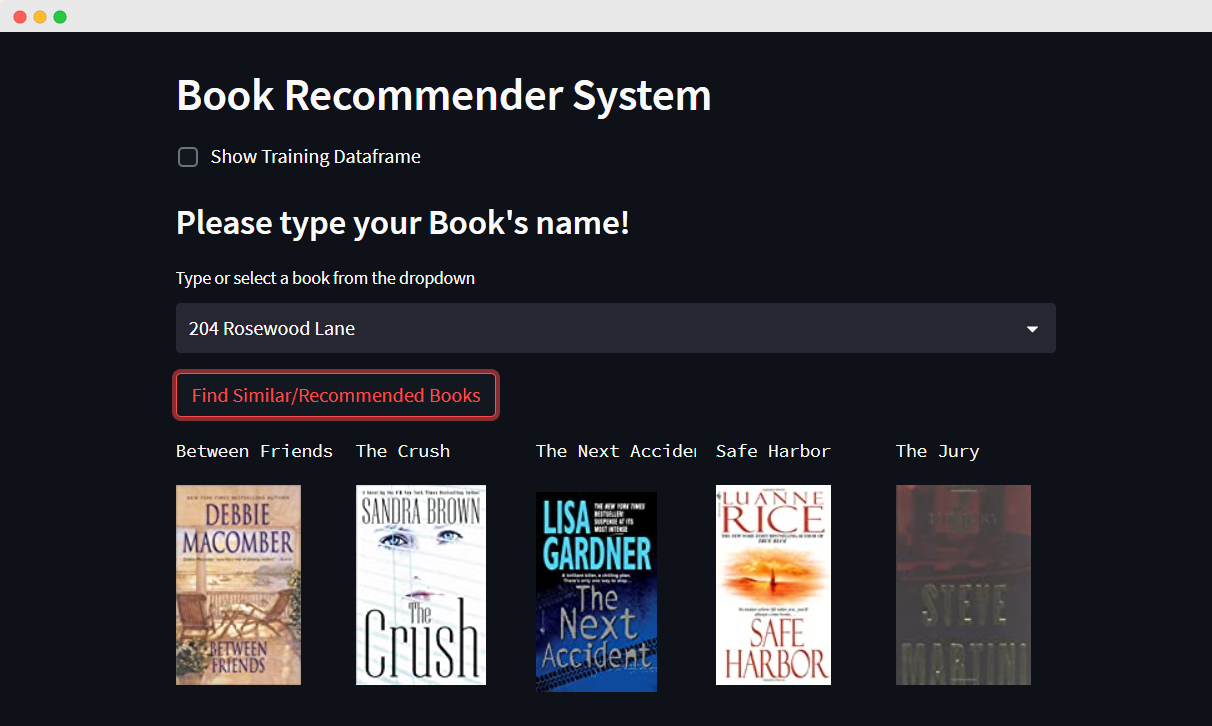
This is an end-to-end ML project based on Book Recommendation Dataset available on kaggle capable of finding similar or recommended books based on collaborative filtering technique(Popularity based RS is included in notebook). Special thanks to TMDDB for making the dataset available publicly on kaggle.

